How to Build a Realtime AI Phone Agent Using OpenAI’s Realtime API

Soheil H
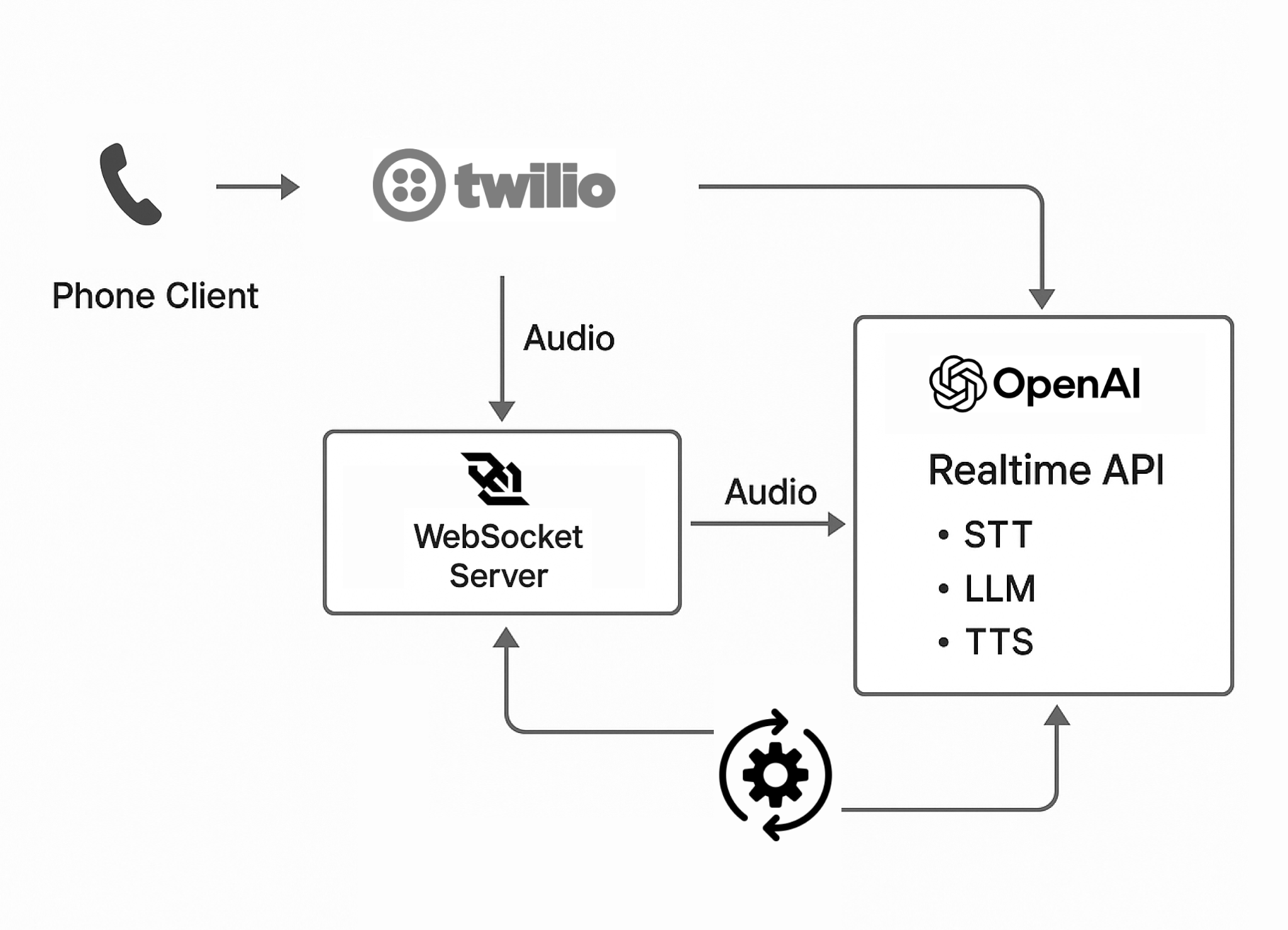
In this guide, we’ll walk through how to build a real-time conversational phone agent using:
- 📞 Twilio for telephony
- 🔁 A WebSocket server to stream audio
- 🧠 OpenAI’s new Realtime API for STT → LLM → TTS
- 🔧 Structured JSON output and conditional call workflows
By the end, your AI bot will answer calls, understand natural speech, speak back in real-time, and trigger custom actions—all in under a second of latency.
Step 1: The Stack You’ll Need
| Component | Role |
| Twilio Voice | Receives phone call and streams audio via <Stream> |
| WebSocket Server | Middle layer that forwards audio to OpenAI and sends audio responses back |
| OpenAI Realtime API | Does transcription, reasoning, and speech in one stream |
| Audio Encoding | μ-law 8 kHz—low latency, no resampling |
| Redis (optional) | Stores call state / partial user data between turns |
| App Logic | Routes responses, triggers SMS or handoffs, logs transcripts |
Step 2: Set Up Twilio Media Streaming
Provision a Twilio number and configure its voice webhook to return this TwiML:
<Response>
<Connect>
<Stream url="wss://yourserver.com/audio"
track="both_tracks"
audioFormat="audio/x-mulaw;rate=8000" />
</Connect>
</Response>
Step 3: Build a WebSocket Server
This server accepts Twilio’s media messages and sends them to OpenAI’s Realtime API.
Key tasks:
- Decode μ-law base64 audio
- Feed raw audio into OpenAI’s Realtime stream
- Listen for partial transcripts and streaming responses
- Re-encode output audio as μ-law base64 and send it back to Twilio
Use libraries like ws, mulaw, and axios or openai-streams to simplify streaming I/O.
Step 4: Stream to OpenAI’s Realtime API
OpenAI’s Realtime API handles:
- Speech-to-text (STT) – partial transcripts as user talks
- LLM reasoning – real-time intent extraction
- Text-to-speech (TTS) – spoken responses as tokens stream back
You can optionally request structured output like:
{
"intent": "schedule_appointment",
"name": "Samantha",
"email": "sam@example.com"
}
Step 5: Add a State Machine or Flow Router
When JSON responses come back from OpenAI, your server can:
- Confirm names or spelled-out words (“J as in John…” → “Jake”)
- Trigger SMS follow-ups using Twilio API
- Escalate the call to a live agent using <Dial>
- Log transcripts into a CRM or backend
Add simple FSM logic with conditions based on intent, confidence, or user corrections.
Step 6: Keep It Realtime (Latency Tips)
To make the AI sound natural and fast:
- Stick to μ-law @ 8000 Hz throughout—no transcoding
- Keep TTS responses short (2–5s of audio)
- Use chunked audio input (20–40ms frames)
- Stream text → audio tokens as soon as they’re ready (don’t wait for full sentences)
- Cancel or barge-in mid-response if user interrupts
Aim for < 1 second roundtrip from user speaking to bot reply.
Bonus: Add Error Handling
Include guardrails like:
- If OpenAI fails or delays, drop to fallback IVR logic
- Validate and parse all returned JSON before acting on it
- Log call metadata with unique StreamSid or CallSid per session
Architecture Summary
Caller → Twilio → WebSocket Server → OpenAI Realtime API
↑ ↓
Speech Out ← TTS ← LLM ← Transcript
↘
Your App (FSM, DB, Routing)
Want to See It Working?
We’ve battle-tested the stack and tuned it to production standards. If you’d like to skip the dev work and get a live AI agent today, try TalkTaps.